简评常见的消息中间件
就像构建程序时我们往往需要一些组件用于结构不同的模块一样,在复杂的分布式系统中,我们使用消息中间件来为不同的组件解耦.这些消息中间件作用归结起来就一个–分发消息.
依据按什么形式分发消息目前主流的就3种结构:
- 消息队列(Queue),用于构建生产消费模式.数据按被生产出来的顺序进入结构,消费端则是先到先得争抢式的获取数据进行消费.
- 广播(Pub/Sub),用于构建发布订阅模式,生产端将数据放入结构后,结构负责将数据分发给所有订阅了的消费端.
- 流(Stream),广播和消息队列的混合,通常用于应付复杂场景的数据分发,生产端和消息队列一样按顺序生产出数据放入结构,消费端则需要分组,不同组和广播一样获得生产出来的所有数据,但组内不同消费者则类似消息队列一样争抢式(也可以是协商式的)的获得数据进行消费.
评估标准
我们评价一个东西不能范范而谈,需要有个标准才好做取舍.下面说明下本文的评估标准
消息可用性
指的是确保消息不丢失能被正常消费的能力
服务可靠性
指的是消息中间件结构本身的可靠性
吞吐量
指的是生产端将数据写入结构的性能
时效性
指的是数据从生产端到消费端的延迟
部署成本
指的是部署消息中间件需要资源的多少
使用成本
指的是开发人员使用起来的学习成本和费劲程度
维护成本
指的是维护消息中间件需要人力的多少
常见消息中间件
业界最常见的消息中间件就3个–redis,rabbitmq,kafka
redis: 使用List数据类型实现消息队列;使用PUBLISH/subscribe构建广播;使用Stream结构实现流rabbitmq: 队列绑定到交换机,消息通过交换机发布到队列中,广播就是发送至绑定的指定复数队列中,rabbitmq的一大优势是支持AMQP和MQTT两种协议,前一种稳定,后一种高性能,另一个优势是支持队列和消息过期kafka: 只支持stream结构同topic可以将消息广播给不同的consumer group,相同consumer group的consumer消费消息而非广播.
下面是这3种消息中间件各项标准的矩阵图
| 消息中间件名 | Redis | RabbitMQ | kakfa |
|---|---|---|---|
| 支持结构 | pub/sub,queue,stream |
queue,stream |
stream |
| 消息可用性 | 无法保证,queue,stream可以借助rdb/aof减少丢失 |
消息不会丢失 | 消息不会丢失 |
| 服务可靠性 | 可以通过主备架构提高可靠性 | 基于主从架构实现高可用 | 天生集群化部署实现高可用 |
| 单机吞吐量 | 百万级 | 万级 | 十万级 |
| 时效性 | 微秒 | 微秒 | 毫秒级 |
| 部署成本 | 高,redis是内存使用大户,数据都是放内存的 | 中 | 低,可以更多的靠集群而不是单机性能 |
| 使用成本 | 默认使用低,如果要做额外的消息确认和防数据丢失就高 | 中 | 高 |
| 维护成本 | 低 | 中 | 高 |
接下来是简单演示,本文将使用上面3种工具实现一个分发随机数求平方和的功能.顺便介绍这三者的一些使用时的注意点.这个例子的流程是这样的:
- 生产者向
sourceQ队列发送数据, - 消费者从
sourceQ队列取数据,消费者计算完成平方后将结果放入队列resultQ - 生产者接收
resultQ队列中的结果更新累加结果并打印在标准输出中 - 广播模式: 生产者在收到
KeyboardInterrupt错误时向频道exitCh发出消息,消费者订阅频道exitCh,当收到消息时退出.
我们使用python作为编程语言,用异步接口来实现上面的例子
redis实现
redis是一个高性能的key-value内存数据库.在其中实现了一些数据结构.这个小东西轻量但高效深受开发者喜爱.redis默认端口6379
redis用什么包我在python攻略中中已经讲过,这边不再复述
本文使用stream结构构建例子,代码在msg-middleware-redis分支
实现功能
-
生产者
from typing import Any from uuid import uuid4 import asyncio import random from aredis import StrictRedis REDIS_URL = "redis://localhost" redis = StrictRedis.from_url(REDIS_URL, decode_responses=True) group = "testconsumer" sourceQ = "sourceQ" resultQ = "resultQ" exitCh = "exitCh" client_id = str(uuid4()) async def xgroup_create(name: str, group: str, *, stream_id: str = '$', auto_create: bool = False) -> Any: """创建绑定用户组到流. Args: name (str): 流名 group (str): 用户组 stream_id (str, optional): 流中的默认读取位置,$表示默认从最近开始读. Defaults to '$'. auto_create (bool, optional): 流不存在是否创建流. Defaults to False. """ if not auto_create: res = await redis.execute_command('XGROUP CREATE', name, group, stream_id) return res if not await redis.exists(name): res = await redis.execute_command('XGROUP CREATE', name, group, stream_id, "MKSTREAM") return res res = await redis.execute_command('XGROUP CREATE', name, group, stream_id) return res async def producer() -> None: try: while True: data = {"source": random.randint(1, 400)} await redis.xadd(sourceQ, data, max_len=100) print(f"send {data} @ {sourceQ}") await asyncio.sleep(1) except Exception as e: raise e async def collector() -> None: """监听结果流获得数据后计算和后打印出来.""" sum = 0 while True: entries = await redis.xreadgroup(group, client_id, count=1, **dict(resultQ=">")) data = entries.get(resultQ) if data: for event in data: eid = event[0] msg = event[1] print(f"received {msg} from {resultQ}") sum += int(msg.get("source")) print(f"get sum {sum}") await redis.xack(resultQ, group, eid) else: await asyncio.sleep(1) async def main() -> None: try: await redis.xinfo_consumers(sourceQ, "testconsumer") except Exception as e: print(f"get err {e}") await xgroup_create(sourceQ, "testconsumer", stream_id='$', auto_create=True) task = asyncio.ensure_future(collector()) try: await producer() finally: task.cancel() if __name__ == "__main__": loop = asyncio.get_event_loop() try: asyncio.run(main()) except KeyboardInterrupt: try: loop.run_until_complete(redis.xadd(exitCh, {"event": 'Exit'}, max_len=10)) except Exception as e: print("$$$$$$") print(e) except Exception as e: raise e -
消费者
import asyncio from uuid import uuid4 from typing import Any from aredis import StrictRedis REDIS_URL = "redis://localhost" redis = StrictRedis.from_url(REDIS_URL, decode_responses=True) maxlen = 100 sourceQ = "sourceQ" resultQ = "resultQ" exitCh = "exitCh" group = "testconsumer" client_id = str(uuid4()) async def xgroup_create(name: str, group: str, *, stream_id: str = '$', auto_create: bool = False) -> Any: """创建绑定用户组到流. Args: name (str): 流名 group (str): 用户组 stream_id (str, optional): 流中的默认读取位置,$表示默认从最近开始读. Defaults to '$'. auto_create (bool, optional): 流不存在是否创建流. Defaults to False. """ if not auto_create: res = await redis.execute_command('XGROUP CREATE', name, group, stream_id) return res if not await redis.exists(name): res = await redis.execute_command('XGROUP CREATE', name, group, stream_id, "MKSTREAM") return res res = await redis.execute_command('XGROUP CREATE', name, group, stream_id) return res async def process() -> None: """监听数据流获得数据后计算平方放入结果流.""" print("process start") while True: entries = await redis.xreadgroup(group, client_id, count=1, **dict(sourceQ=">")) data = entries.get(sourceQ) if data: for event in data: eid = event[0] msg = event[1] print(f"received {msg} from {sourceQ}") result = {"source": int(msg.get("source"))**2} await redis.xadd(resultQ, result, max_len=100) print(f"send {result} @ {resultQ}") await redis.xack(sourceQ, group, eid) else: await asyncio.sleep(1) async def main() -> None: try: await redis.xinfo_consumers(sourceQ, group) except Exception as e: print(f"get err {e}") await xgroup_create(sourceQ, group, stream_id='$', auto_create=True) try: await redis.xinfo_consumers(resultQ, group) except Exception as e: print(f"get err {e}") await xgroup_create(resultQ, group, stream_id='$', auto_create=True) task = asyncio.create_task(process()) print("watch exitCh start") await xgroup_create(exitCh, client_id, stream_id='$', auto_create=True) try: while True: entries = await redis.xreadgroup(client_id, client_id, count=1, **{"exitCh": ">"}) signals = entries.get("exitCh") if signals: print("get exit signal from producer") for signal in signals: eid = signal[0] msg = signal[1] print(f"received signal {msg}") await redis.xack("exitCh", client_id, eid) break else: await asyncio.sleep(0.1) finally: await redis.xgroup_destroy(exitCh, client_id) task.cancel() print("exit") if __name__ == "__main__": asyncio.run(main())
使用时的注意事项
Redis本质上是个缓存工具,只是它提供的结构刚好也可以用来做消息中间件.我们看上面的矩阵图可以发现,最适合使用redis的场景有两个:
- 对实时性要求极高,但对消息可用性没什么要求的场景.比如股票交易系统里面用来分发买入卖出信号,因为错过了也就没意义了.
- 原型实现或者快速实现的场景.充分利用使用维护成本都低的优势先把系统搭起来试错,然后再迁移去其他成本更高的工具.反正原型阶段数据量小,部署成本上的劣势也不明显.
在低版本的redis中是没有stream结构的,但很早之前很多工程师就利用redis做消息中间件解耦了.所以至今在使用redis做消息中间件这个领域中依然是queue和pub/sub的天下.不过个人还是更建议如果是新系统还是用stream结构,因为更加容易向其他比如kafka这类的上迁移.
在作为队列时,redis用list类型的值存储要处理的数据,由于list是一个双向链表,我们可以在左边插入也可以在右边插入,也可以在左边取出也可以在右边取出,因此可以以此构造先进先出或者先进后出队列.而List本身最大长度为$232-1$,redis对于数据需要注意redis的list是可能阻塞的,阻塞原因各种各样,可能因为数据同步,可能因为内存不足.
而redis的redis的pub/sub实现相当简单,它只是将订阅者的套接字存放在一个list中,当有消息来时顺次每个都发一遍而已.因为不会保留发布出去的内容,所以发布订阅是无法回溯的.
这两种结构由于没有ack机制而无法保证消息一定到达消费端也不能很好的保证消息一致性.当然我们可以在redis的基础上通过各种手段给它加上ACK机制,加上边界检查等,这会大大增加开发成本,就违背其初衷了.
redis stream结构的注意事项
stream结构则是上面两者结合的威力加强版.它的key类型为stream.在stream类型中有几个概念:
stream流结构,表现为一个key,它会存储数据consumer group,消费者组,这个结构实际上维护一个消费者和流之间的关系映射.同一个stream的数据会广播给不同的group;同一个group中的消费者,只有一个能拿到这个数据consumer,消费者ID流中数据的唯一标识
通常有两种工作流:
先生产再消费
- 生产者使用
XADD key [MAXLEN|MINID [=|~] threshold [LIMIT count]] *|ID field value [field value ...]将数据直接写入stream从而创建一个stream类型的key. 这一步的注意事项有两个,一是指定stream的最大长度.有三种选择:- 不填
如
XADD mystream * ... entry fields here ...,不设限制 - 直接填一个大于0的整数.
如
XADD mystream MAXLEN 1000 * ... entry fields here ...,表示严格限制,也就是超过这个条数就会立即删除,这会影响流的性能 - 填
~ limit如XADD mystream MAXLEN ~ 1000 * ... entry fields here ...,表示大体限制,这会在尽量不影响流性能的前提下让条数大致符合设置
使用
stream结构时我们应该考虑好存储长度,内存是非常贵的资源,因此长度最好别太长,redis毕竟是个缓存.个人经验预估个1个小时的量就好.如果需要更长时间跨度的数据保存,建议弄个消费者组专门监听消息然后按批把数据写到时序数据库里二是指定消息的id号,有两种选择:
- 由redis生成, 如
XADD mystream * ... entry fields here ... - 自己指定,如如
XADD mystream 0-0 ... entry fields here ...,需要注意id必须是由两段int64的数字中间通过-连接形成.
- 不填
如
- 消费者组使用
XGROUP CREATE key groupname stream_id将消费者组绑定到key. 这一步需要注意的是stream_id的设置,它决定了这个用户组中用户从key的什么位置获取数据,有3种选择:$,用户永远只能获得最新的数据0表示从头开始获取数据ID,用户从指定ID的这个位置开始获取数据
- 消费者使用
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]来监听这个key. 这一步注意点有:COUNT一次读取的批大小,这也决定了系统的处理性能,BLOCK控制获取数据的同步异步特性有三种选择:- 如果不提供则不阻塞,直接返回当前监听的状态,没有就为空
- 如果
block 0则表示永久阻塞直到有数据来 - 如果是
block x,为大于0的整数,则表示最多等待x毫秒,收到什么就返回什么,如果啥也没有就返回空
NOACK如果设置,消息被读取时就会执行XACK,否则我们就需要在业务执行结束后手工ack,通常在要求数据被完全正确消费的场景下我们都不会设置它ID的设置也是两种情况:>,只拿最新消息- 指定id,需要注意,指定id的话前面设置的
BLOCK和NOACK就都失效了
先消费再生产
- 消费者组使用
XGROUP CREATE key groupname stream_id MKSTREAM将消费者组绑定到key,同时创建一个0长度的stream并使用XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]来监听这个key. - 生产者使用
XADD key [NOMKSTREAM] [MAXLEN|MINID [=|~] threshold [LIMIT count]] *|ID field value [field value ...]将数据写入stream.如果要确保这个stream是已经创建好的,可以加上NOMKSTREAM.
ack机制
stream结构自带ack机制.如果我们在读取流的时候没有设置NOACK,那么我们就必须在处理完执行过程后手工使用XACK key group ID [ID ...]来告诉redis这条数据消费完了.
但如果有消费过程报错未能ack的怎么处理呢?
比较常见的方法是使用一个定时任务(比如5分钟执行一次)专门处理长时间未ack的数据.思路是这样的:
- 使用
XPENDING key group [[IDLE min-idle-time] start end count [consumer]]定时获取当前指定group在指定stream中未被ack的消息信息,主要包括- 消息id
- 接收了消息的消费者名
- 消息未ack持续的时间(毫秒)
- 消息被发出去的次数
- 利用上面的信息找出(6.2版本后可以用上面的命令直接通过
IDLE过滤)超时超过特定时间的消息 - 有几种处理:
- 将超时的消息通过
XCLAIM key group consumer min-idle-time ID [ID ...] [IDLE ms] [TIME ms-unix-time] [RETRYCOUNT count] [FORCE] [JUSTID]转发给其他消费者消费掉 - 观察消费者未能ack的频次,适当的使用
XGROUP DELCONSUMER mystream consumer-group-name myconsumer123将已经崩了的消费者从组中删除 - 确认是不是消息本身有问题,如果是就用
XDEL key ID [ID ...]将消息删除
- 将超时的消息通过
rabbitmq实现
rabbitmq就是一个标准的传统消息队列了.它虽然不及redis实时性好,不及kafka吞吐量好,但它可以做复杂的路由,而且还有数据过期功能等非常实用的功能,性能稳定,就像数据库领域中关系数据库之于非关系数据库一样,是大多数场景下最应该考虑使用的消息队列.
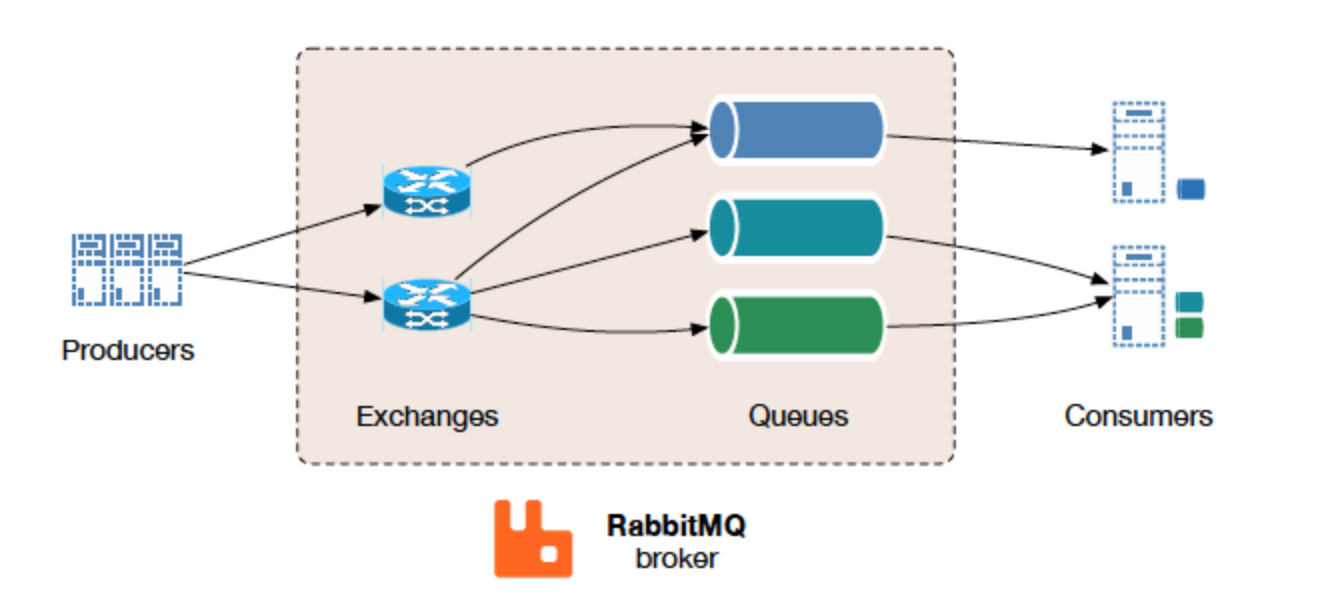
rabbitmq默认的用户名和密码是guest:guest,可以在端口15672查看到管理页面.
它支持两种协议
AMQPAdvanced Message Queuing Protocol,专业的消息队列应用层协议,默认端口5672和5671MQTT物联网领域常用的消息队列协议,只有发布订阅模式,专为硬件性能低下的远程设备以及网络状况糟糕的情况而设计,默认端口1883或8883,这种协议本文不介绍以后如果谈到IOT领域我们再回来谈
rabbitmq虽然没有stream结构,但通过交换机和队列可以组合出stream结构的效果,而且更加灵活.这个例子的实现代码在msg-middle-rabbitmq分支
实现功能
虽然官方推荐的工具是pika,但这个AMQP实现太过陈旧,都是基于回调的而且其堵塞接口不是线程安全的用起来很恶心,本文使用aio-pika,一个基于python3.5+异步工具的客户端.
我们的实现如下:
-
生产者
import random import asyncio import aio_pika AMQP_URL = 'amqp://guest:guest@localhost:5672/' async def producer(channel): while True: data = random.randint(1, 400) await channel.default_exchange.publish( aio_pika.Message(body=str(data).encode()), routing_key="sourceQ" ) print(f"send {data} to sourceQ") await asyncio.sleep(1) async def collector(Q): sum = 0 async with Q.iterator() as queue_iter: # Cancel consuming after __aexit__ async for message in queue_iter: async with message.process(): print(f"received {message.body}") sum += int(message.body) print(f"get sum {sum}") async def pubExt(): print("exit publishing") connection = await aio_pika.connect_robust(AMQP_URL) async with connection: exitCh = await connection.channel(2) ex = await exitCh.declare_exchange('exitCh', type=aio_pika.exchange.ExchangeType.FANOUT) await ex.publish(aio_pika.Message(body=b"Exit"), routing_key="") print("exit published") async def main(): connection = await aio_pika.connect_robust(AMQP_URL) async with connection: # Creating channel channel = await connection.channel(1) # type: aio_pika.Channel await channel.declare_queue("sourceQ") resultQ = await channel.declare_queue("resultQ") prodcor = producer(channel) collcor = collector(resultQ) await asyncio.gather(prodcor, collcor) if __name__ == "__main__": print("producer start") try: asyncio.get_event_loop().run_until_complete(main()) except KeyboardInterrupt: asyncio.get_event_loop().run_until_complete(pubExt()) finally: print("done") -
消费者
import uuid import asyncio import aio_pika AMQP_URL = 'amqp://guest:guest@localhost:5672/' async def consumer(sourceQ, channel): async with sourceQ.iterator() as queue_iter: # Cancel consuming after __aexit__ async for message in queue_iter: async with message.process(): print(f"received {message.body}") result = int(message.body.decode("utf-8"))**2 await channel.default_exchange.publish( aio_pika.Message(body=str(result).encode()), routing_key="resultQ" ) print(f"send {result} to resultQ") async def main(): connection = await aio_pika.connect_robust(AMQP_URL) async with connection: # Creating channel channel = await connection.channel(1) # type: aio_pika.Channel sourceQ = await channel.declare_queue("sourceQ") await channel.declare_queue("resultQ") exitCh = await connection.channel(2) extE = await exitCh.declare_exchange('exitCh', type=aio_pika.exchange.ExchangeType.FANOUT) q_id = str(uuid.uuid4()) extQ = await exitCh.declare_queue(q_id, auto_delete=True) await extQ.bind(extE) task = asyncio.ensure_future(consumer(sourceQ, channel)) async with extQ.iterator() as queue_iter: async for message in queue_iter: async with message.process(): print(f"received {message.body}") if message.body == b"Exit": task.cancel() return if __name__ == "__main__": print("consumer start") asyncio.run(main())
使用时的注意事项
rabbitmq有这么几个关键概念:
-
channel每个频道由交换机和队列组成,可以定制多个交换机和多个队列,通常用于区分业务 -
exchange交换机,生产者生产的消息的发送入口,用于定义消息分发的规则–即一条消息发布出来后应该放入哪些队列,有3种常用的模式:Direct Exchange处理路由键需要将一个队列绑定到交换机上,要求该消息与一个特定的路由键完全匹配.如果一个队列绑定到该交换机上要求路由键’dog’则只有被标记为’dog’的消息才被转发.Fanout Exchange不处理路由键.只需要简单的将队列绑定到交换机上,一个发送到交换机的消息都会被转发到与该交换机绑定的所有队列上.很像子网广播,每台子网内的主机都获得了一份复制的消息.Fanout交换机转发消息是最快的.Topic Exchange将路由键和某模式进行匹配.此时队列需要绑定要一个模式上.符号#匹配一个或多个词;符号*匹配不多不少一个词.比如audit.#能够匹配到audit.irs.corporate.audit.*只会匹配到audit.irs.
另外每个
channel都会有一个特殊的默认exchange,当你手动创建一个队列时后台会自动将这个队列绑定到一个名称为空的Direct类型交换机上,绑定路由名称与队列名称相同. -
queue消费者订阅消息的入口,每个queue需要定义一个路由键用于让交换机做匹配.每个队列中一条消息只能被一个订阅者消费掉
rabbitmq在各个方面都很均衡,几乎可以使用在任意场景,是这三种中最常用的默认选择.
下面是rabbitmq的几个最佳实践:
-
保证队列中有尽量少的消息堆积(redis也适用)
当队列中堆积过多消息时会给内存带来极大的压力,为了释放内存Rabbit会将消息刷至磁盘,当有大量消息需要刷新至磁盘时,会造成队列的阻塞进而影响系统吞吐量.
-
启用懒惰队列功能
懒惰队列会将生产者的消息持久化到磁盘中而不驻留在内存,只有当消息需要被消费时才会重新加载到内存. 这可以很好的避免内存过高.当然也是有代价的,引入磁盘必然会降低实时性并增加io负担因此如果要求实时性就不要开了. 如果惰性队列中存储的是非持久化的消息,内存的使用率会一直很稳定,但是重启之后消息一样会丢失. 当设置了队列最大长度时也应该禁用队列的lazy属性.
-
持久化消息与队列
如果你期望消息不丢失,那么需要将队列声明为
durable的,并且发送的消息也要声明为persistent(二者必须同时设置)这样在broke发生故障重启后消息就不会丢失. -
设置max-length或者TTL
对于那些吞吐量优先,允许消息丢失的应用程序最好设置这两个属性(队列最大长度和消息过期时间)避免消息堆积来保证内存正常.
-
队列数量
rabbit中的队列是单线程的,适当使用多个队列和消费者可以增加吞吐量.但不要设置太多的队列.如果底层节点上的队列与内核一样多则可以实现最佳吞吐量.
-
自动删除不使用的队列
有如下几种方式自动删除不使用了的队列
- 可以在队列上设置TTL策略.
- 设置了自动删除属性的队列.最后一个消费者取消或连接关闭设置了自动关闭的队列就会被删除
- 设置独占队列.独占队列只能被声明他的连接所使用.当声明连接关闭或消失时将删除独占队列.
-
设置优先级队列的优先级上限
在大多数情况下,不超过5个优先级就足够了
-
消息确认机制
如果不需要确保消息不丢失,把消息确认机制关掉可以提高吞吐量;如果开启了消息确认,接收到重要消息的消费应用程序在完成对这些消息的任何处理(工作程序崩溃,异常等)之前都不应该确认消息.发布确认类似于消息确认机制,服务器在收到来自发布者的消息时进行ack.发布确认对性能也有影响.但是如果生产者需要确保消息到达broker,那么它是必需的.由于所有未确认的消息必须驻留在服务器的内存中.如果有太多未确认的消息就会耗尽内存.限制未确认消息的有效方法是设置客户端预取值,即
prefetch_count的值. -
Prefetch预取值
prefetch属性用来定义一次可以给消费者发送多少条消息,设置合适的值会使消费者得到有效利用.默认情况下预取值为无限大,这意味着消费者尽可能的接收生产者的消息.预取值限制了消费者在确认消息之前可以接收多少消息.所有预获取的消息都将从队列中删除,并且对其他消费者不可见.假如prefetch_count值设为10且消费者开启acknowledge,获取10个消息后rabbitmq不再将队列中的消息推送过来.当对消息处理完后(即对消息进行了ack,并且有能力处理更多的消息)再接收来自队列的消息. 预取值过小会降低rabbit的性能;预取值过大时当存在多个消费者,可能会导致某个消费者负载过高,而其他的消费者处于空闲状态.
关于预取值的建议:如果消费者数量不多并处理迅速可以将预取值设的大一些,保证消费者充分使用;如果消费者数量较多,且处理时间较短,可以将值取的比上个情况下稍小一些.如果消费者较多且处理时间较长,建议将预取值设为1以便各个消费者”负载均衡”.具体的数目可以在机器上进行测试,然后选取合适的值.总之尽量不使用系统默认的预取策略.最后最重要的一点是预取值只有在手动确认模式下才生效.
kafka实现
kafka是一个追求高吞吐的分布式消息队列.和redis比较是另一个极端,几乎是为复杂而生:
- 天生支持分布式,并且它必须依赖
zookeeper维护集群一致性(按官方计划3.0版本以后将不再使用zookeeper). - 天生持久化,硬盘允许情况下保留所有消息.
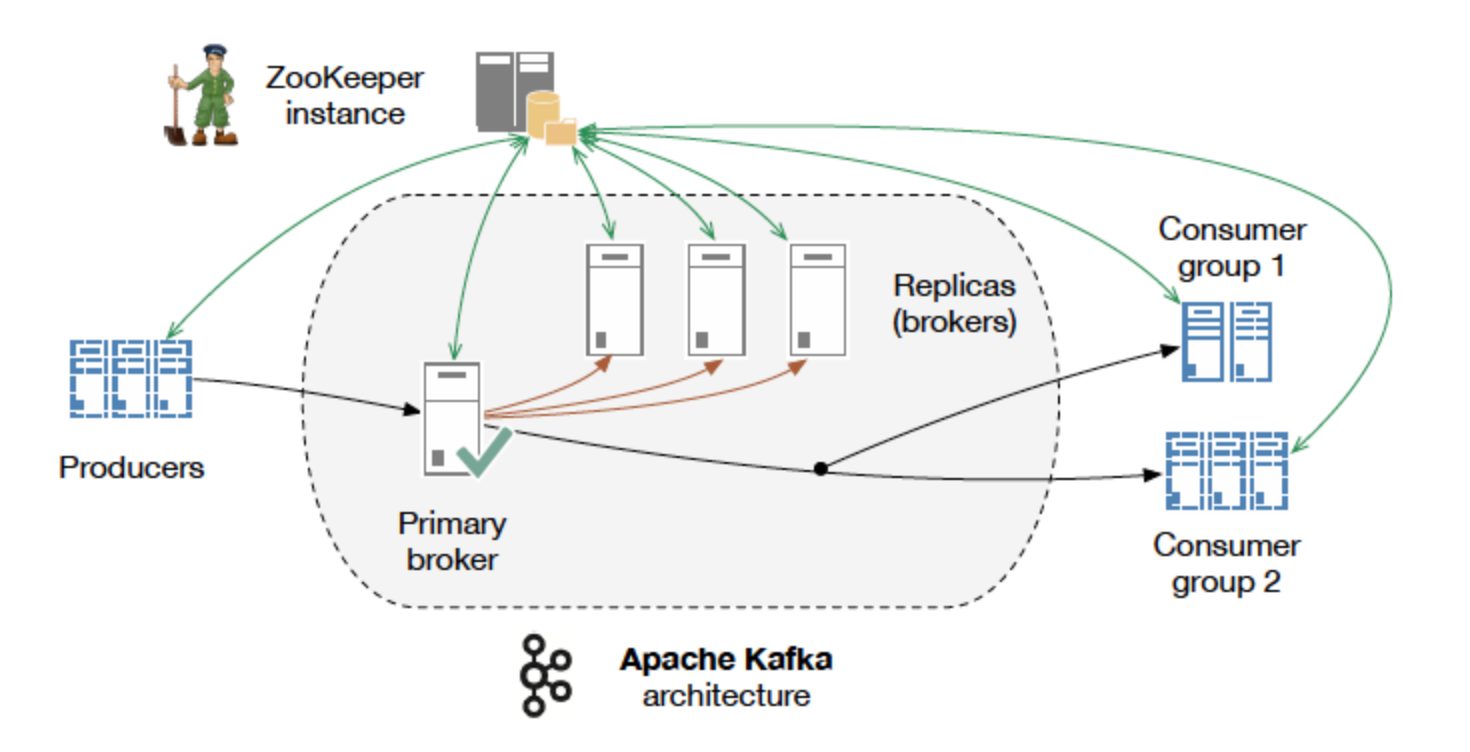
我们在本地可以使用docker部署一个用于测试,kafka默认端口为9092.
- docker-compose.yml
version: '3.6'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_CREATE_TOPICS: "topic1:1:1"
volumes:
- /var/run/docker.sock:/var/run/docker.sock
使用docker-compose up -d启动就可以在localhost:9092访问到kafka了
这个例子的实现在msg-middleware-kafka分支
实现功能
kafka的异步接口可以使用aiokafka
- 生产者
import sys
import random
import asyncio
from aiokafka import AIOKafkaProducer
from aiokafka import AIOKafkaConsumer
loop = asyncio.get_event_loop()
sourceQ = "sourceQ"
resultQ = "resultQ"
exitCh = "exitCh"
kfkproducer = AIOKafkaProducer(loop=loop, bootstrap_servers='localhost:9092')
consumer = AIOKafkaConsumer(resultQ,loop=loop, bootstrap_servers='localhost:9092',group_id=resultQ)
async def push(Q, value):
await kfkproducer.send_and_wait(Q,str(value).encode())
print(f"send {value} to {Q}")
async def producer():
while True:
data = random.randint(1, 400)
await push(sourceQ, data)
await asyncio.sleep(1)
async def collector():
sum = 0
async for msg in consumer:
print(f"received {msg}")
sum += int(msg.value.decode("utf-8"))
print(f"get sum {sum}")
async def main():
task = asyncio.ensure_future(collector())
print("start")
await producer()
if __name__ == "__main__":
loop.run_until_complete(kfkproducer.start())
loop.run_until_complete(consumer.start())
try:
loop.run_until_complete(main())
except KeyboardInterrupt:
loop.run_until_complete(push(exitCh, "Exit"))
except Exception as e:
raise e
finally:
loop.run_until_complete(kfkproducer.stop())
loop.run_until_complete(consumer.stop())
loop.run_until_complete(loop.shutdown_asyncgens())
loop.close()
- 消费者
import sys
import uuid
import asyncio
from aiokafka import AIOKafkaProducer
from aiokafka import AIOKafkaConsumer
loop = asyncio.get_event_loop()
kfkproducer = AIOKafkaProducer(loop=loop, bootstrap_servers='localhost:9092')
sourceQ = "sourceQ"
resultQ = "resultQ"
exitCh = "exitCh"
async def push(Q, value):
await kfkproducer.send_and_wait(Q, str(value).encode())
print(f"send {value} to {Q}")
async def get_result(producer):
PARTITION_0 = 0
consumer = AIOKafkaConsumer(sourceQ, loop=loop, group_id=sourceQ, bootstrap_servers='localhost:9092')
await consumer.start()
try:
async for msg in consumer:
print(f"received {msg}")
data = int(msg.value.decode("utf-8"))
await push(resultQ, int(data)**2)
finally:
await consumer.stop()
async def main():
await kfkproducer.start()
try:
asyncio.ensure_future(get_result(kfkproducer))
group_id = str(uuid.uuid4())
print(f"group_id:{group_id}")
consumer = AIOKafkaConsumer(exitCh, loop=loop, group_id=group_id, bootstrap_servers='localhost:9092')
await consumer.start()
try:
async for msg in consumer:
print(msg)
if msg.value == b"Exit":
sys.exit(0)
finally:
await consumer.stop()
finally:
await kfkproducer.stop()
if __name__ == "__main__":
try:
loop.run_until_complete(main())
except Exception as e:
raise e
finally:
loop.run_until_complete(loop.shutdown_asyncgens())
loop.close()
使用时的注意事项
kafka是相当复杂的,但其接口还是比较简单的.只是我们得分清如何设置才能达到自己想要的效果.kafka中有3个概念:
-
Brokerkafka的宿主机节点,由于kafka是分布式系统,通常会有超过一台宿主机. -
topic订阅的主题.类似于redis中的流,用来区分隔离不同的消息数据,屏蔽了底层复杂的存储方式.对于大多数人来说,在开发的时候只需要关注数据写入到了哪个topic,从哪个topic取出数据.
-
partition分区和replicationFactor复制因子,partition分区是Kafka下数据存储的基本单元,而replicationFactor复制因子则控制每个partition的副本数量.同一个topic的数据会被分散的存储到多个partition中,而这些partition又会保存多份副本以增加数据冗余性以提高容灾能力,这些partition可以在同一台机器上.也可以是在多台机器上.但通常相同partition的副本会分散在各个Broker上.每个相同的partition会有一个leader,平时的读写,以及复制数据到副本都是由它进行,当这个leader崩溃时其他副本将会投票确定一个新的leader.
partition的数量通常是Broker数量的整数倍,而其副本也不会放在相同的Broker上.通常可以认为
partition副本的数量决定了生产者的写入性能(同时影响的还有写入时的ack机制);而由于partition数量决定了有效consumer的上限,因此partition的数量决定了消费者的读取性能.通常对于b个broker节点和复制因子为r的kafka集群,整个kafka集群的partition数量最好不超过
100*b*r个,即单个partition的leader数量不超过100 consumer group,和redis中一样,消费者组Kafka实现单播和广播两种消息模型的手段.同一个topic的数据会广播给不同的group;同一个group中的消费者,只有一个能拿到这个数据.consumer group负责数据的分发的规划,在新增或者减少consumer时会对数据的分配规则自动做出调整consumer,消费者,kafka中通常要求每个consumer group中consumer的个数要小于监听topic的partition数量.producer,生产者,将数据保存到分区的组件Offset,消息的唯一序号,类似redis中的id概念
topic和partition是1对多关系;topic和consumer group是多对多关系;consumer可以是consumer group的一员也可以不是.
一个topic的一条信息是怎么到消费者手中的呢:
生产者写入
- 将信息放入topic下的一个partition的leader中
如何确认该发给哪个partition呢?kafka使用如下规则:
- 如果发送时指定则发送到指定的partition
- 如果未指定,但有指定的key字段,则使用公式
hash(key)mod(num(partitions))确定发送到哪里 - 如果都没指定,则使用
round-robin算法均匀分发给不同的partition
-
leader写入好后将数据复制到它的副本中
-
leader向生产者确认收到消息.
确认机制可以在生产者一端设置
ack参数实现,有3种选择:0,只要发出去了不管是否接收到都认为发送成功,这种方式可以最大化吞吐量,但无法保证数据不丢失1,只等待leader写入成功就确认,leader崩溃且其他副本还没来及同步的话消息丢失.这种方式会有小概率数据丢失的情况.-1(all)等待leader写入完成且副本也都同步完成后再完成确认,这种方式会比较影响吞吐量,但可以确保数据不丢失
消费者读取
消费者根据消费者组的分配规则从特定的几个partition的leader中读取数据,消费完成后消费者还需要向kafka确认消费了消息
和传统的消息系统不一样的是,Kafka只能保证单个partition内的数据顺序不变,但看topic的化消息就是无序的,如果非要保证顺序,那我们的topic就只能有一个分区(不推荐).
消息丢失和重复问题
消息丢失和重复问题一般都出在消息确认上,我们可以看到kafka中有两处消息确认–生产者和消费者
生产者的消息确认
生产者一端数据丢失的情况一般都是设置了ack为-1或者1,但出现重复一般也是因为上面的设置,因为一旦ack失败,如果有配置的话,kafka的生产者就会触发重试.有两种解决方法:
-
设置
retries为0,相当于快速失败,这虽然不会造成kafka中的数据丢失,但会造成业务数据丢失,谨慎使用. -
消息设置key并启用幂等(相同数据造成的结果一致)特性.
我们已经知道了key可以用于确认分区,只要设置了key则说明分区就是固定的了.而kafka还提供了同一分区上的幂等性设置,可以确保写入同一分区的数据只会写入一次.设置方法是设置
enable.idempotence=true,但不要设置transactional.id
消费端的消息确认
消费端的消息确认就很像redis streram的xack了.kafka提供了与消费端消息确认相关的配置包括:
enable.auto.commit默认值true,表示消费者会周期性自动提交消费的offsetauto.commit.interval.ms在enable.auto.commit为true的情况下,超过auto.commit.interval.ms间隔后,下一次调用poll时会提交所有已消费消息的offset.默认值5000ms.。max.poll.records单次消费者拉取的最大数据条数,默认值500max.poll.interval.ms默认值5分钟,表示若5分钟之内消费者没有消费完上一次poll的消息,那么consumer会主动发起离开group的请求
一般出问题出在第四个选项代表的功能上.我们的消费者每次执行的顺序是
- 先poll下来指定数量的数据
- 处理所有数据
- 处理完成后提交offset.
但如果超过max.poll.interval.ms设置的时间限制没有提交offset的话,消费者就会自动离开消费者组,消费者组就会进行rebalance重新分配消息给其他消费者.如果之前的消费者实际上已经执行好了但就是没来得及提交offset,那就会造成重复消费.
如何解决呢?
两个思路:
-
让消费跟上提交
方法有4种
- 提高消费效率,比如单条数据操作改批操作,向量化操作,换更加高效的编程语言,io写入操作都改成批写入等
- 增加分区数量提高并行度,增加消费者数量同时减小
max.poll.records - 提高
max.poll.interval.ms
前两种都是在尽量想办法跟上数据生产的速度,而第三种则是通过降低生产数据到达消费端的速度来实现的.因此第三种容易造成数据堆积
-
让消费者确认数据不重复
方法有两种:
- 消费者确保操作幂等
- 消费者一端借助其他有状态服务比如将offset作为主键将结果保存在数据等确保碰到重复数据不被消费者执行.