使用Git管理你的代码
Git是当前最流行的一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目.
它是Linus Torvalds为了帮助管理Linux内核开发而开发的一个开放源码的版本控制软件.
Git最大的特点是分布式.它与以往集中式的版本控制工具最大的不同就是Git的仓库是相互独立的,每个人电脑中都有完整的版本库,所以某人的机器挂了并不影响其它人.这一特性天生对开源软件亲和.
Git的工作流程
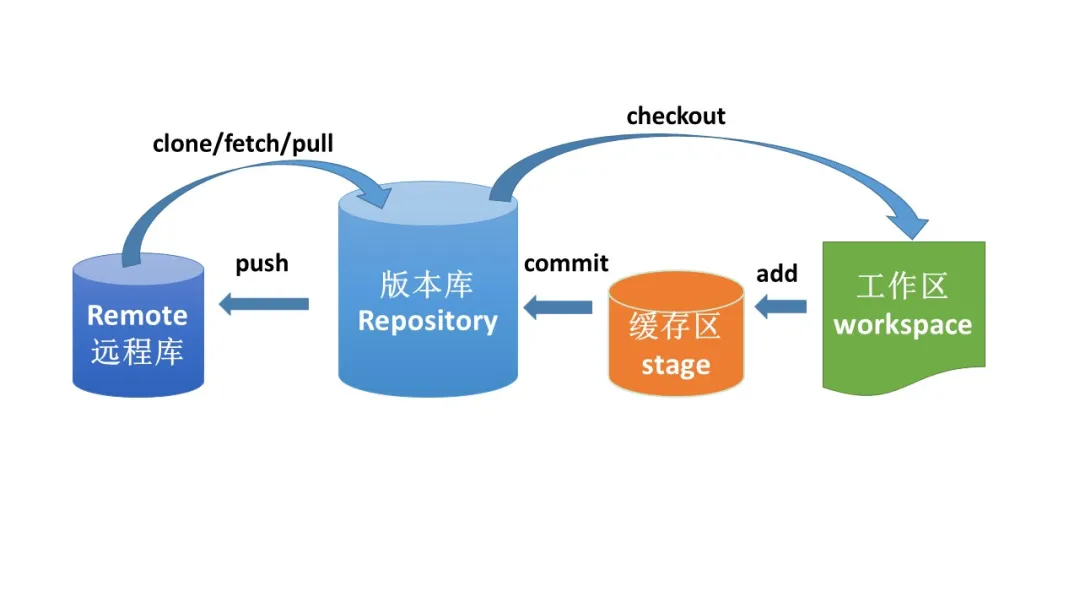
git版本控制系统由工作区,缓存区,版本库组成.它跟踪的是文件的修改而不是全部文件.也就是说它的版本控制靠的是记录变化.因此相比较起管理二进制文件,git更擅长管理代码等文本文件.
本文大量参考了Pro Git一书.感谢作者和翻译人员.
基本的版本控制
Git是分布式代码仓库,但如果只是本地使用也完全可以用于项目的版本控制.
但无论怎样你都需要先在本地创建一个代码仓库.
创建一个git的项目仓库
git init
创建本地仓库后项目根目录下会生成一个.git的文件夹,其中config文件会记录仓库的一些基本信息.项目会有一个HEAD文件用于记录当前的状态.
这个HEAD会指向一个分支,一般是master分支,分支这个概念我们会在下一单元介绍.
设置禁止追踪名单
我们可以在Git项目下创建.gitignore文件用于描述哪些文件的状态不进行追踪.其语法规则是:
配置语法:
- 以斜杠
/开头表示目录 - 以星号
*通配多个字符 - 以问号
?通配单个字符 - 以方括号
[]包含单个字符的匹配列表 - 以叹号
!表示不忽略(跟踪)匹配到的文件或目录 #代表注释
一个典型的.gitignore文件如下:
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
env/
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
*.egg-info/
.installed.cfg
*.egg
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
.hypothesis/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# Jupyter Notebook
.ipynb_checkpoints
# pyenv
.python-version
# celery beat schedule file
celerybeat-schedule
# SageMath parsed files
*.sage.py
# dotenv
.env
# virtualenv
.venv
venv/
ENV/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
typecheck/
# vscode
.vscode/
setup.py
docs/.DS_Store
.DS_Store
提交缓存
git add <path>
创建完成后就是写要管理的项目.我们需要向Git提交缓存变更才能让它记住.只有缓存了的代码才能被管理.我们可以使用add子命令将指定路径下的文件/文件夹的修改提交到缓存.为了方便,比较方便的方式是git add .
一般情况下我们会在确定没问题的情况下做add操作,但如果要取消缓存也不是没有办法可以使用如下命令
git reset HEAD <file>...
这条命令会将当前的缓存区中指定的文件缓存删除.
提交缓存的最佳实践是每次只在提交变更前提交缓存,这样就可以直接使用变更来管理版本.
提交变更
git commit -m <message>
当多个缓存定型后我们可以提交一版修改到git,这步会生成了当前项目的一个快照,这个快照用一串字符串唯一标识(commitID),并将项目当前的HEAD指向这个提交的commitID.并将缓存区清空.
每次的提交都会包含如下信息:
commitID唯一标识Author如果有设置的话Date提交的日期- message 提交时附带的信息
- 文件差异信息
查看提交历史变更
这个信息只要不人工干预就不会被修改删除.依据这个我们可以得到一个由提交串起来的历史提交时间序列.如何查看提交历史呢?
git log
如果添加flag-p -{n}就可以查看每次提交所引入的差异,后面的-{n}是展示多少条
另一种方式是使用flag--stat,它可以看到每次提交的变化统计信息.其他还有几个flag可以用于设置展示形式这里就不详细介绍了,如果感兴趣可以看这篇.
回退到指定提交
由于每次的快照都会保存且有唯一标识,因此在本地我们可以随时回退到之前的某一次提交上.这就实现了版本控制.
-
reset(不推荐)第一种方式是回退操作
git reset --hard HEAD^ 回退到上个版本 git reset --hard HEAD~3 回退到前3次提交之前,以此类推回退到n次提交之前 git reset --hard <commitID> 退到/进到指定commit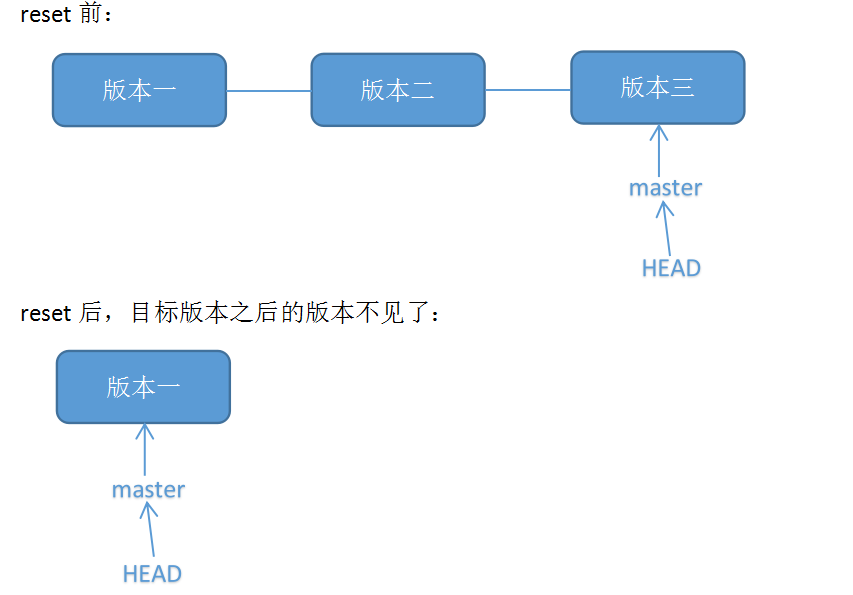 注意回退会修改提交历史树,也就是说回退操作是无法撤销的.
注意回退会修改提交历史树,也就是说回退操作是无法撤销的.如果我们希望保留这个历史或者实际上我们只是要撤销某词提交的内容,那么可以使用
-
revertrevert准确说并不是回退,而是获取撤销某次提交的结果和当前的状态做合并,并生成一次新的提交.因此它并不会改变提交历史.git revert HEAD 撤销当前HEAD指定的提交的修改 git revert <commitID> 撤销个指定commit的修改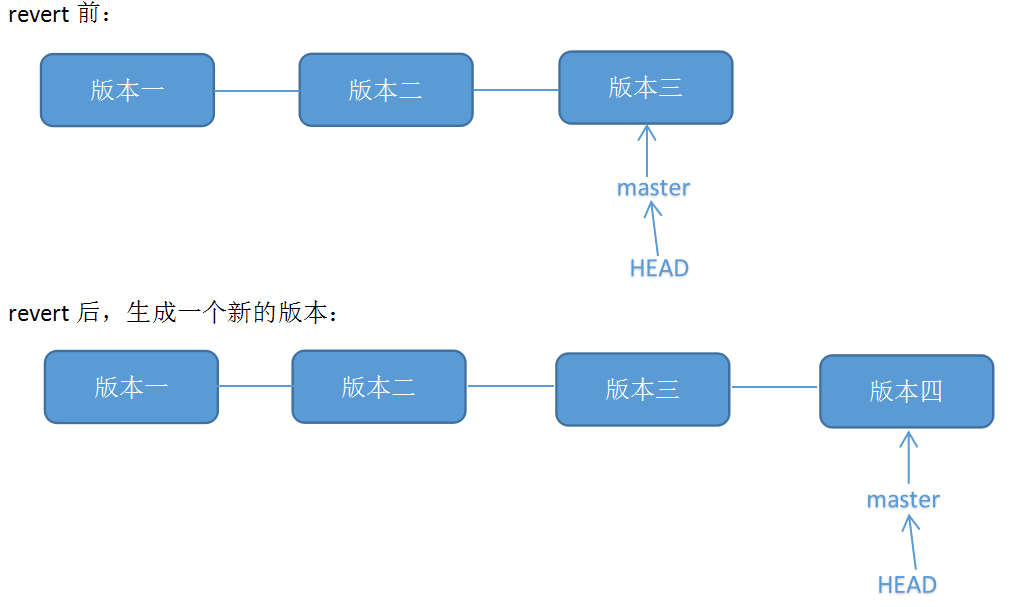
git revert由于实际上是合并操作,所以可能会造成冲突.如果有冲突就和下面的merge一样解决即可
使用分支隔离代码
我们可以通过迁出分支来实现代码隔离,比如我们希望功能a和功能b同步开发,同时又担心开发过程中相互影响干扰,那么就可以迁出两个分支a和b.迁出的分支会指向迁出之前commitID.之后这个分支就时基于这次提交的修改了.
创建分支
git branch <分支名>
迁出分支会在当前分支下创建一个新的分支指向当前的commitID
这操作我们也可以使用git checkout -b <分支名>它会在创建新分支之外同时将HEAD指向这个新分支.
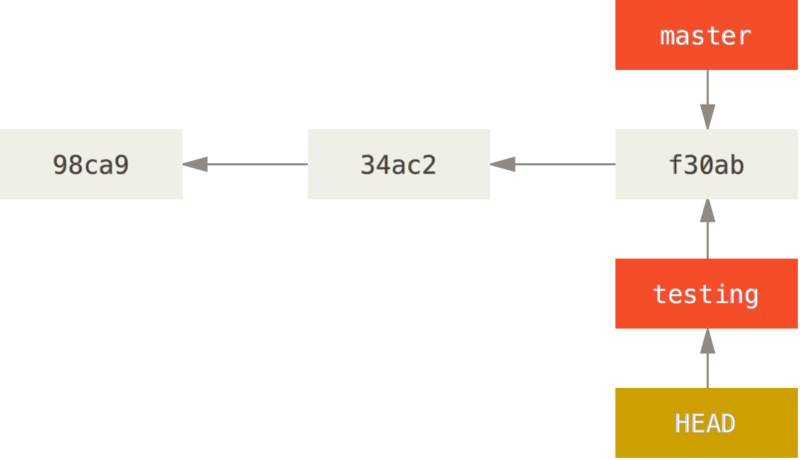
实际上仓库创建起来后就会默认创建一个master分支,无论后面迁出什么分支都可以认为根源上都是来自master分支,由于Head是指向分支再由分支保存最近的commitID的,所以在一个项目中可以每个分支保留自己的最终状态而不相互影响.
查看分支列表
我们可以使用
git branch
来查看当前所在分支和当前仓库中有哪些分支
切换分支
要在这些分支间切换可以使用
git checkout <分支名>
删除分支(不推荐)
当然我们可以删除一些已经无用的分支
git branch -d <分支名>
合并分支
每次创建一个分支有个专用的说法叫项目分叉,这也就是说项目会在每次创建新分支时出现新的走向.当新的走向需要回归主干时就需要合并分支操作
git merge <目标分支名>
这个合并操作的目的是将目标分支合流到当前分支.因此实际上涉及到的提交点有3个:
- 当前分支的最近提交
- 目标分支的最近提交
- 两个分支的分叉点
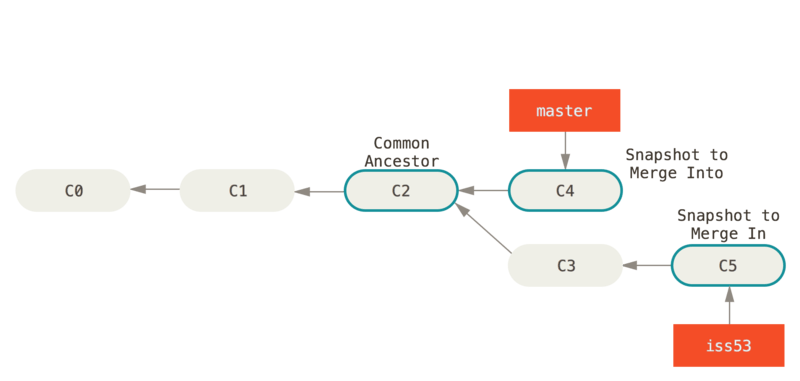
合并分支的基本逻辑是将这3者的进行对比
- 如果没有冲突则直接合并变更生成一次提交,这次提交称作
合并提交,同时你的当前工作区就成了合并后的样子. -
如果有冲突则需要先在工作区解决冲突,之后使用
git commit手动提交.git merge命令执行后要合并的分支中文件都会被放入共工作区,同时会标注冲突源,我们只需要将所有冲突源解决就算是解决了冲突. 有哪些冲突可以通过使用git status查看,其中有冲突的文件会被标识为unmerged.文件中有冲突的部分进行标注(冲突文件中使用<<<<<<<,=======和>>>>>>>标识冲突来源).现代的编程辅助工具比如vscode,github desktop等都会有明确提示帮助你解决冲突.
取消合并分支
取消合并分支本质上也是回退提交,因此和上面一样也是reset和revert两种方式.我们以下面的分支结构举例
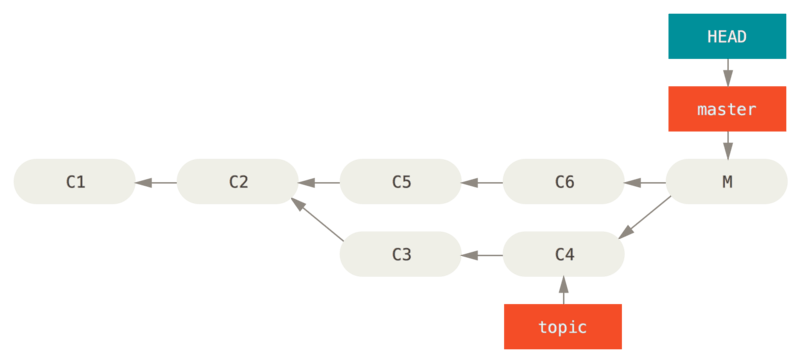
-
reset方式(不推荐)git reset --hard HEAD~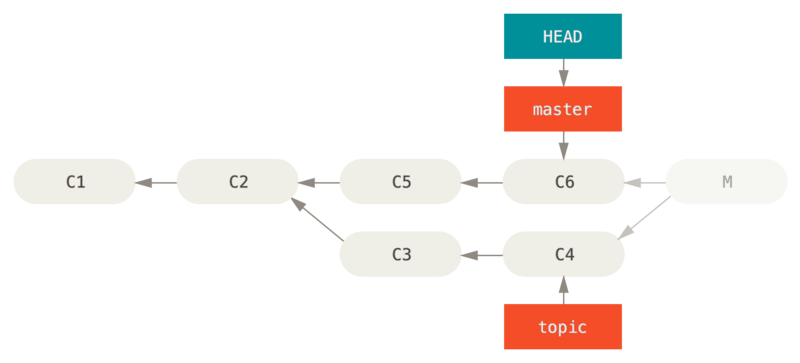
-
revert方式由于撤销的分支合并,因此会带来一些麻烦点,下面是如何解决这些麻烦点
-
撤销合并
git revert -m 1 HEAD-m 1标记指出”mainline”需要被保留下来的父结点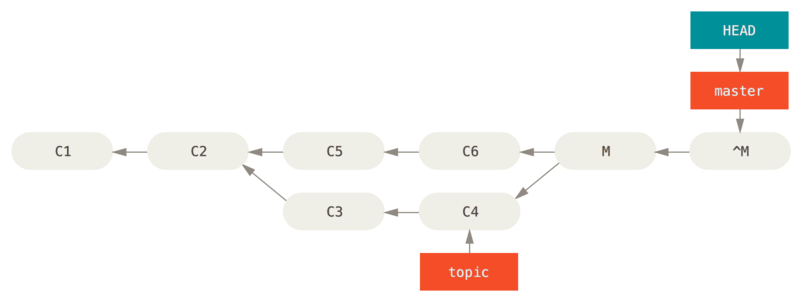
-
撤销
撤销合并以便再次从分支中合并事实上这样撤销合并后如果我们的
topic分支修改了一版提交C7后想再合并进master会提示Already up-to-date.. 如果要让C7可以真的合并进master我们需要额外做一次撤销操作来撤销刚才的撤销合并.git revert <^M的id>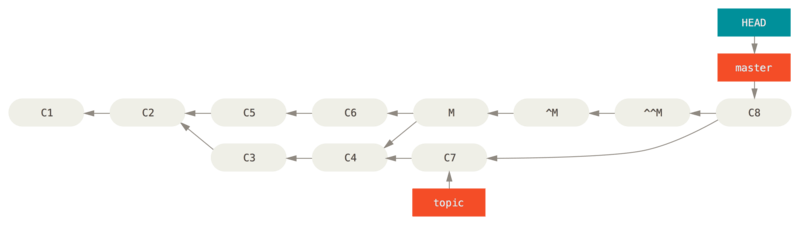
-
分支变基(不推荐)
分支合并还有一种方式是变基,不要想歪了….它的作用是将指定分支上的的所有修改都移至另一分支上,就好像”重新播放”一样.以下面的分支结构为例
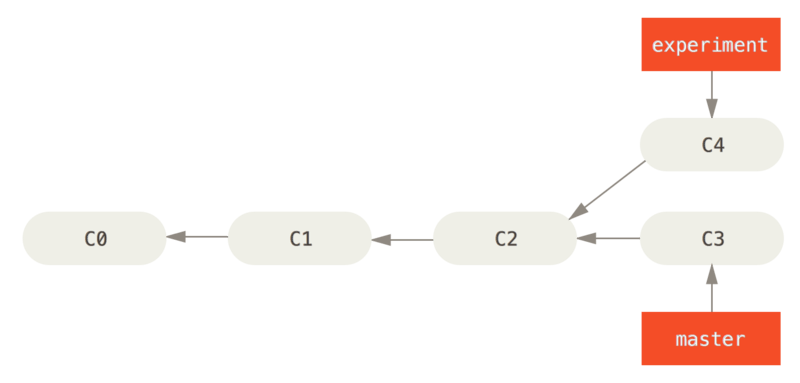
我们在experiment分支上执行git rebase master.它的原理是首先找到这两个分支(即当前分支experiment,变基操作的目标基底分支master)的最近共同祖先C2,然后对比当前分支相对于该祖先的历次提交,提取相应的修改并存为临时文件,然后将当前分支指向目标基底C3, 最后以此将之前另存为临时文件的修改依序应用.这样最终我们所在的experiment分支就跑到了master分支的前面,而之前在experiment的提交就都删除了
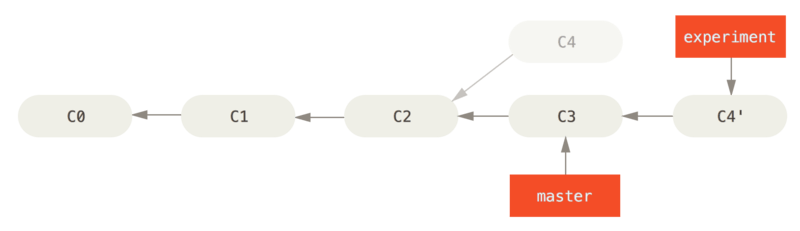
如果要将experiment分支合回master,再切回master执行git merge experiment就行了.
使用分支的最佳实践
将分支分类处理
通常我们会将分支分为两种:
-
长期有效的分支 他们一般会有固定的作用,并且更进一步的可以和持续集成持续交付有关.比如通常
master分支要求是长期存在,并且要一直是最近的稳定可执行版本,dev分支一般会要求是最近的可执行开发版本等等,这些定义一般根据不同的工作流模型会有不同的分工. -
短期特性分支
这种分支只会在有特定需求时出现,而且必须尽快合并回长期有效分支.一般来说这类分支的作用无外乎几种:
- 紧急修复
- 增加小特性
- 小范围的代码优化
这类短期特性分支一定要尽快合并进长期有效分支.
使用
merge而不是rebase合并分支
我们一般不做变基操作,,变基操作会修改提交记录,虽然可以让你的提交历史树看起来更美观些但不利于历史追踪查询问题和回退.
使用
revert而不是reset方式来回退合并提交.
理由和上面一样,我们应该尽量的保证提交历史树的真实性和完整性.
使用标签固定版本
如果你隔离代码的目的不是分出一枝继续开发而是单纯的留档,那么分支并不是最优雅的解决方案.标签更合适.
可以简单理解标签是不能修改的分支.管标签操作的命令是git tag.
- 查看列表使用
git tag -l - 创建使用
git tag -a <tag名> -m <message>,这回将当前的HEAD指向的提交打上标签.- 如果使用轻量标签可以直接
git tag <tag名>,注意轻量标签不会有这个操作的元信息. - 如果想将历史上的某一次提交打标签可以使用
git -a <tag名> -m <message> <commitID>
- 如果使用轻量标签可以直接
- 删除使用
git tag -d <tag名>
从标签开始”修改”代码
我们可以使用git checkout <tag名>来迁出标签指定的提交.但是注意标签迁出的代码修改后提交是无效的.
因此如果要进行修改需要先基于标签创建一个分支(git checkout -b <分支名>),然后在分支中修改代码.
远程仓库同步
Git的作用当然不是只在本地做做版本管理.它毕竟是分布式版本控制系统,是为协作而生的.如何与远程仓库协同才是它最主要解决的问题.
裸仓库
像上面介绍的都是常规仓库,它会有工作区,缓存区,版本库.而远程仓库一般都是裸仓库(bare repository).它没有工作区,即你不能直接在这样的仓库里进行正常的git命令操作.这种仓库只能接收和修改历史提交树.
裸仓库的作用就是作为众多分布式仓库的中心仓库.它的作用就是让连接它的本地仓库可以共享代码.
创建一个裸仓库
git init --bare
这个操作一般并不是在本地执行,而是在托管仓库的服务器上. 我们可以使用开源的git服务比如gitea或者gitlab来自己搭建git服务.也可以借助比如Github来实现.
虽然Git是分布式版本管理工具,但无论再怎么分布式去中心化,项目的版本管理都是服务于完成项目这一目标的.而要完成项目必然需要将分散在各处的代码聚合在一起统一发布.这也是中心仓库的意义.
由于一个本地仓库可以关联多个远程仓库,因此中心仓库也不一定是完全中心化的.多数Git托管服务都有Fork和Pull Requests功能,因此也可以使用多中心仓库的方式隔离代码.这个会在后面补充介绍.
配置你的Git
Git本身的账户系统并不是用于做权限管理的,它只是记录提交历史树上提交是由谁发起的.但作为版本管理工具,单纯的记录明显远远不够,更何况提交历史树是可以修改的.
这里说的Git的账户实际上指的是git服务上注册的账户信息.
Git可以通过配置文件来设置包括账户信息在内的一系列内容.这些配置可以通过修改各级配置文件来实现.Git加载配置的优先级按项目级>用户级>系统级来.
-
项目级
每个Git项目下的
.git/config文件 -
用户级
linux/macOS上是
~/.gitconfig或~/.config/git/config;windows上是C:\Users\$USER\.gitconfig -
系统级
linux/macOS上是
/etc/gitconfig;windows上要看安装位置,比如我的就是是C:\Program Files\Git\etc\gitconfig
一个典型的配置文件如下:
[filter "lfs"]
clean = git-lfs clean -- %f
smudge = git-lfs smudge -- %f
process = git-lfs filter-process
required = true
[user]
name = HUANG SIZHE
email = hsz1273327@gmail.com
[core]
editor = \"C:\\Users\\hsz12\\AppData\\Local\\Programs\\Microsoft VS Code\\Code.exe\" --wait
[init]
defaultBranch = master
[credential]
helper = store
配置用户相关的主要就是
[user]
name = HUANG SIZHE
email = hsz1273327@gmail.com
[credential]
helper = store
user部分用于配置用户名和邮箱credential.helper=store意思就是保存用户所用的密码,这样只要输入一次就后面就不再需要输入了.
另一种不太安全的用户登录方式是修改项目级配置中的[remote "origin"]下的url,在host前面直接明文写上用户名密码,比如:
[remote "origin"]
url = http://username:password@hostname:port/xxxxx.git
明文方式并不推荐,但在一些时候可以应急.
远程仓库管理
一个项目可以有不止一个远程仓库,但如果有的话一定会有一个被命名为origin.通常它就是这个仓库设置的第一个远程仓库.
我们可以使用git remote -v来查看远程仓库的情况
git remote -v
origin https://github.com/hsz1273327/hsz1273327.github.io.git(fetch)
origin https://github.com/hsz1273327/hsz1273327.github.io.git(push)
可以看到我们远程仓库名,对应的路径以及支持的操作.
我们也可以在项目的config文件中找到对应配置
[remote"origin"]
url=https://github.com/hsz1273327/hsz1273327.github.io.git
fetch=+refs/heads/*:refs/remotes/origin/*
远程仓库的增删改查操作如下:
| 操作 | 命令 |
|---|---|
| 添加 | git remote add <仓库名> <url> |
| 删除 | git remote remove <仓库名> |
| 修改名字 | git remote rename <仓库名> <仓库新名字> |
| 查看详情 | git remote show <仓库名> |
关联远程仓库
本地和远程仓库关联有两种情况
-
本地没有仓库
如果本地没有仓库,一张白纸好做文章,我们可以使用
git clone命令将远程仓库克隆到本地git clone [-b <branch-or-tag-or-commit> [--single-branch]] [--depth <n>] <url> [本地path]- 如果缺省本地path,那么
git clone命令会将克隆来的仓库放在执行目录下的远程仓库同名文件夹下. - 我们可以通过使用
-b <branch-or-tag-or-commit>来指定希望clone下来在工作区的是哪个分支/tag/提交,否则就会直接将远程仓库的HEAD作为我们的工作区. - 如果我们只需要特定提交的代码.可以在上面的基础上使用
--single-branch.这样其他的分支呀提交的就不会被下载下来. - 我们也可以使用
--depth <n>限制clone的深度,比如说n为1,则只会获取分支上最近一次提交的信息.
一般情况下直接clone就可以了,上面列出的几个参数是在远程仓库过大的情况下我们不想花费大量时间下载可以使用的方案.
- 如果缺省本地path,那么
-
本地已经有仓库了
另一种情况是我们本地已经有了一个仓库,现在希望将这个仓库的代码托管到远程Git服务上.这时我们就需要先在远程Git上创建一个空的仓库.然后将本地仓库和远程的建立关联. 我们可以用上面的添加远程仓库的方式来关联:
git remote add <仓库名> <url>之后我们需要推送本地的分支到远程仓库:
git push -u origin --all git push -u origin --tags建立起关联后,项目的config也会有响应的记录:
[branch"master"] remote=origin merge=refs/heads/master [branch"dev"] remote=origin merge=refs/heads/dev ...
推送和拉取代码
本地和远程仓库间的交互更加常见的是拉取和推送操作.
拉取
拉取分为两种:
gitfetch,远程获取最新版本但并不merge到本地,你需要手工修改后手工提交.gitpull,远程获取最新版本并merge到本地
他们的基本操作类似,都可以使用-f强制覆盖本地.当缺省仓库名时默认就是拉取的origin仓库的内容,缺省分支名时则时拉取当前分支.
git pull/fetch [-f] [仓库名 [分支名...]]
推送
推送就是使用git push命令
git push [-f] [仓库名 [分支名...]]
和上面拉取类似,使用-f强制更新,仓库名和分支名则是用于指定推送的目标
无论是推送还是拉取,正常情况下我们都不应该使用-f,合并代码虽然心累但是很有必要.
如果我们希望把本地的tag都提交了可以使用命令git push [仓库名]--tags
远程分支管理
远程分支管理依然是使用的git branch和git checkout命令,只是和本地操作略有不一样
git branch -a查看远程分支列表git checkout -b 本地分支远程仓库名/远程分支切换到远程分支,注意由于本地没有远程分支,所以需要新建本地分支,也就有了-b 本地分支这个部分
如果希望本地和远程分支名一致也可以使用git checkout --track 远程仓库名/远程分支
git branch -r -d 远程仓库名/远程分支删除远程分支(不推荐)git push --set-upstream 远程仓库名远程分支本地有但远程仓库没有的分支推送到远程仓库,注意这个操作需要在那个要push的分支下进行
远程tag管理
远程tag的管理比较特殊,只有推送和删除,而且全部使用的是git push命令
git push [仓库名] <标签名>推送本地tag到远程仓库git push origin :<标签名>,注意在执行这步之前,我们需要先删除本地的对应标签:git tag -d <标签名>
PullRequest
PullRequest本质上并不是Git的功能,而是Git服务的功能,在Git中我们是向远程仓库推送新代码,而PullRequest是一个反向的操作,是我们请求远程仓库的管理员将代码合并这个远程仓库.
在gitlab语境下这个功能叫MergeRequest我觉得其实是更贴切的.
PullRequest适用于两种情况:
- 同一远程仓库的分支请求合并进另一个分支.这通常用在特性分支要合并进主干分支的场景上.
- 远程仓库的分支请求合并进另一个远程仓库的一个分支.这通常用在fork的仓库要将改进代码合并回原仓库的情况下.
PullRequest解决了一个什么问题呢?就是代码质量的控制问题,因为请求合并这个操作只是请求,项目的管理者可以控制是否真的要合并进来,而PullRequest是会带上代码差异的,者就可以做codereview了.
可视化工具Github Desktop
Github公司开发的Github Desktop工具是一个全平台的Git可视化工具,使用它可以告别大部分的命令行操作.同时如果你使用的是Github也可以直接在上面做Pull Request,相当方便.
常见的工作流模板
有了工具我们还要有使用工具的方法论才能利用好它.用的好的团队可以做到让整个开发过程毫无停顿,开发人员各司其职相互毫不干扰,而用不好的团队可能反而会因为引入了Git增加复杂性让开发效率打折扣. 我见过很多团队都用git做代码仓库,但真正用的好的相当的少.
这里的差距当然不都是Git工作流本身造成的,但毫无疑问工作流的设计合理性直接决定了团队开发流畅程度的上限,因为从项目管理到CI/CD基石都在工作流上.
接下来介绍几种个人实践过且常见的工作流模板,当然了,没有银弹!.不同的工作流模板适应的场景不同,不要一味套用.
题外话:敏捷开发中衡量软件开发的指标
要说一个工作流是否高效应该要有一个标准.根据不同的场景肯定指标的定义是不一样的. 针对比较常规的场景我们基本可以使用敏捷开发中定义的衡量软件开发有四个关键指标来作为评价标的.
- 交付时间,越短越好
- 部署频率,越高越好
- 平均故障恢复耗时,越少越好
- 变更失败率,越低越好
说到底无论是工具的变更还是方法论的变更都可以理解为是为了提高这4个方面的效率,本文中介绍工作流模板是这个目的,后面文章介绍CI/CD工具以及Docker相关工具都是这个目的.
主干分支策略(trunk-baseddevelopment)
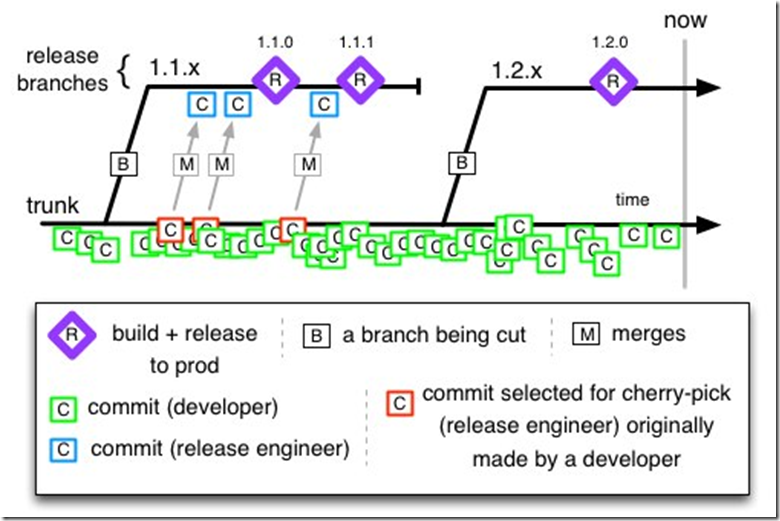
主干分支策略是PaulHammant2013年提出的模型,本质上并不是很有Git风格,本质上它是把Git当SVN这类集中式代码管理工具用.但如果是企业使用却是最好上手的方式,虽然开发人员会反感.
在git种使用主干分支通常就是如下设置:
master分支用于作为主干专门用来开发release-<主版本号>分支用于作为抽出的分支用于发布- 在
release-<主版本号>分支上打tag用于留档
主干分支策略的特点是主干用于开发,分支用于发布.所有人在主干上开发意味着每次提交代码都需要做代码合并操作,小步快跑可以避免长时间隔离开发后合并代码没有头绪的问题(但是开发人员会很厌烦频繁合并代码).通常主干分支上开发新功能是通过代码级别的开关激活的,这样也可以避免不稳定的功能过早引入发布版本造成问题(虽然不优雅).
主干的优点主要是:
- 避免了合并分支的麻烦.
- 非常适合接入CI/CD工具,只需要在主干分支上做持续集成,在发布版本上做持续交付即可,简单.
- 可以确保每个人都了解项目的细节而不是只知道自己的部分.这可以在成员有变动后可以快速有人填补.
当然缺点当然也非常明显:
- 由于只在主干分支上做push操作,这也就意味着需要每个成员都自觉审查自己的代码,而不能由主管做codereview以评估代码是否应该合入主干.难以保证代码质量
- 主干分支策略要求成员都了解项目,这对后进项目的成员相当不友好,如果项目代码架构模块化做的不好则需要较长时间的学习才能融入,而且这种学习依赖于注释和文档.
- 新功能的管理会比较麻烦,要知道很多时候需求是变化的,并不是定了一个新功能就会真的需要让他实现,很多时候新功能只是尝试,没有分支控制会比较麻烦.
- 串行的工作流,明显主干分支策略是一种串行的工作流,只有一次提交,CI走完,改完后下一次提交才能拉取到真正可用的代码,这条实际是第一条缺点的衍生.这很不适合分布式的开发模式.
- 如果要更改底层依赖需要进行大量的修改,如果项目架构模块化做的不好,这种无法一次解决的冲突会让整个开发停滞.
上面的缺点1和4可以通过使用PullRequest来解决,但由于项目内的PullRequest并没有强制性所以也只是缓解而已.总结来说:
- 主干分支策略比较适合10人以下小规模集中化管理的团队,且对成员专业性要求比较高.如果要在更大规模的团队中使用必须项目模块化做的非常好.
- 而且比较适合目标明确不太需要探索新功能的项目.比如:硬件驱动项目,嵌入式项目.
GithubFlow
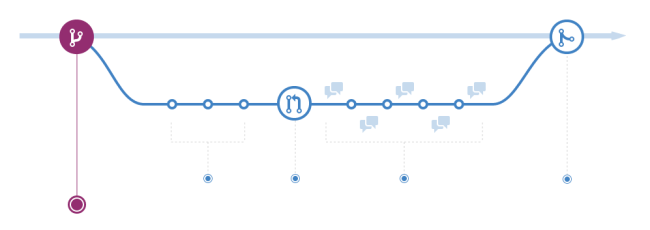
GithubFlow是github官方推荐的工作流模式,它可以看作是主干分支策略的反面,本质上是特性分支策略加Devops,但因为依赖于pullrequest功能.它也只有一个主干分支,但它的逻辑可能更加极端–没有版本,所有可部署版本都在主干分支上,因为本身有commitID所以根本不需要有版本号,因为有PullRequest和CI/CD工具所以可以放心的合并到主干.
GithubFlow的流程可以概括为如下:
- 从主干抽出特性分支用于开发.这个特性分支有具体含义,比如是一个issue.
- 与特性分支描述相关的开发就都在这个特性分支上进行.
- 提交代码后请求
PullRequest合并进主干 - 审查提交的代码,给出评估,驳回直到通过审查.
- 部署提交的代码.
- 合并进主干分支.
GithubFlow完全基于CI/CD工具,因此其优点本质上就是CI/CD的优点
- 完全的自动化的测试和部署带来极短的交付时间,团队熟练的情况下部署跟不上代码合并的速度.
- 由于特性分支含义明确所以一般都是短分支,代码合并的代价低
- 特性分支一般都是和issue关联,因此问题追溯起来方便
- 由于特性分支都是从可部署的主干抽出来的,且都有明确含义,因此合并时比较不容有冲突,即便有冲突也不会太难解决.
- 由于特性分支都是从可部署的主干抽出来的,所以完全可以在隔离的环境中开发,因此可以并行化开发.
- 因为有
PullRequest所以可以控制代码质量.
当然还是那句话没有银弹,GithubFlow的缺陷主要也来自于CI/CD:
- 必须要有整套稳定的CI/CD解决方案,这个不是开发团队的问题,但这往往是最大的问题,国内多数企业的对开发的概念还停留在上个世纪,没有意识到这个东西的强悍
- 必须完全自动化,和上面一条一样,很多时候即便有了CI/CD方案,企业也不会愿意完全自动化,他们会担心没有人参与不可控.
- 必须非常重视测试,测试必须覆盖全面且完全自动化.毕竟是直接部署的,一旦出问题就会直接影响线上.这个和上面一样,往往不是开发的问题而是企业的问题,至少国内不注重测试的企业非常多.
- 随着团队人数的增多及成熟度的提高,开发速度会越来越快.往往一个部署尚未完成另一名开发者就已经处理完下一个pullrequest,开始实施下一个部署.在这种情况下一旦正式环境出现问题很难分辨哪个部署造成了影响.为了应对该情况建议在部署实施过程中通过工具加锁.同时应该刻意控制项目团队的规模.
- 由于所有可用版本都在主干分支上,我们不能将代码按版本发布留档,当然了这可以通过
tag实现. - 解决长时间未合并入主干的分支基本只能废弃.由于迭代过快长时间未合并进主干的分支可能会落后主干相当多,可能合并代码的代价比重写都大.
总结来说:
- GithubFlow适合团队规模15-20人之内的团队,且必须充分信仰DevOps
- GithubFlow适合特性驱动的项目.比如像github这种的线上服务项目.如果将抽出分支和合并分支改为
fork|PullRequest则也可以应用在开源项目上.
GitFlow
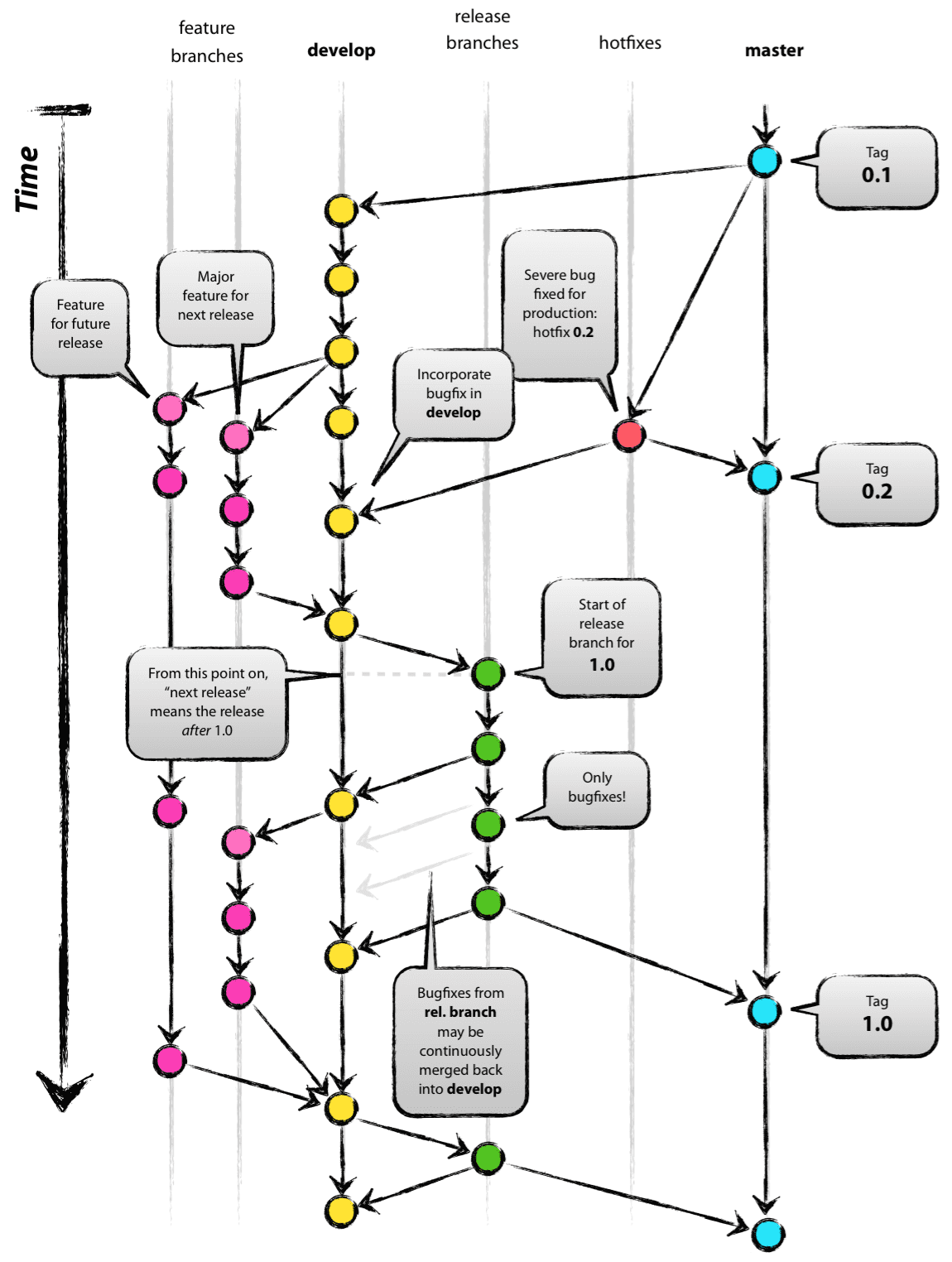
GitFlow是目前网上知名度相当高的一个工作流模板,它可以理解为不依赖CI/CD的减速复杂版GithubFlow.
它的特点是复杂,有两条长期分支,3类短期分支
| 类型 | 从哪个分支创建 | 什么时候创建 | 合并到哪个分支 | 什么时候删除 | 分支数量 |
|---|---|---|---|---|---|
| master | NA | 项目最开始 | NA | 永不删除 | 一个 |
| dev | NA | 项目最开始 | NA | 永不删除 | 一个 |
| release | dev | 准备发布新版本 | dev ,master | 正式发布新版本,代码合并到dev和master之后 | 数量不定 |
| feature | dev | 新功能需要较长时间的协同开发 | dev | 新功能开发完成,合并到dev之后 | 数量不定 |
| hotfix | master | 当生产版本报出bug | dev ,master | 修复经过测试,代码合并到dev和master之后 | 数量不定 |
- master分支时常保持着软件可以正常稳定运行的状态.由于要维护这一状态,所以不允许开发者直接对master分支的代码进行修改和提交.和Github Flow一样,需要提交
Pull Request,通常其中每个节点都会打tag以作留档 - develop分支是开发过程中代码中心分支,维系着开发过程中的最新代码.与master分支一样,这个分支也不允许开发者直接进行修改和提交.开发要以develop分支为起点新建feature分支.
- 和Github Flow中一样,开发在feature分支中进行新功能的开发或者代码的修正.我们应该尽量保证分支的含义明确,并且要足够短.
- release分支用于维护预发布的版本.
- hotfix分支用于解决线上紧急修复.
Git Flow的优点是
- 不依赖CI/CD工具
- 不同分支类型语义明确且各种情况的解决方案覆盖很全,也可以方便的在不同分支嵌入CI/CD脚本
- 虑了紧急Bug的应对措施
- 由于有一个dev分支的缓冲,所以相对来说发布更加安全.也可以支持更大的开发团队.
缺点也同样明显:
- 过于复杂,学习成本较高,需要额外的流程管理.
- Github Flow中存在的长周期特性的问题一样没有解决.
总结来说:
- Github Flow比较适合较大的有专门流程管理的团队
- Git Flow适合开发周期较长的传统商业软件项目.